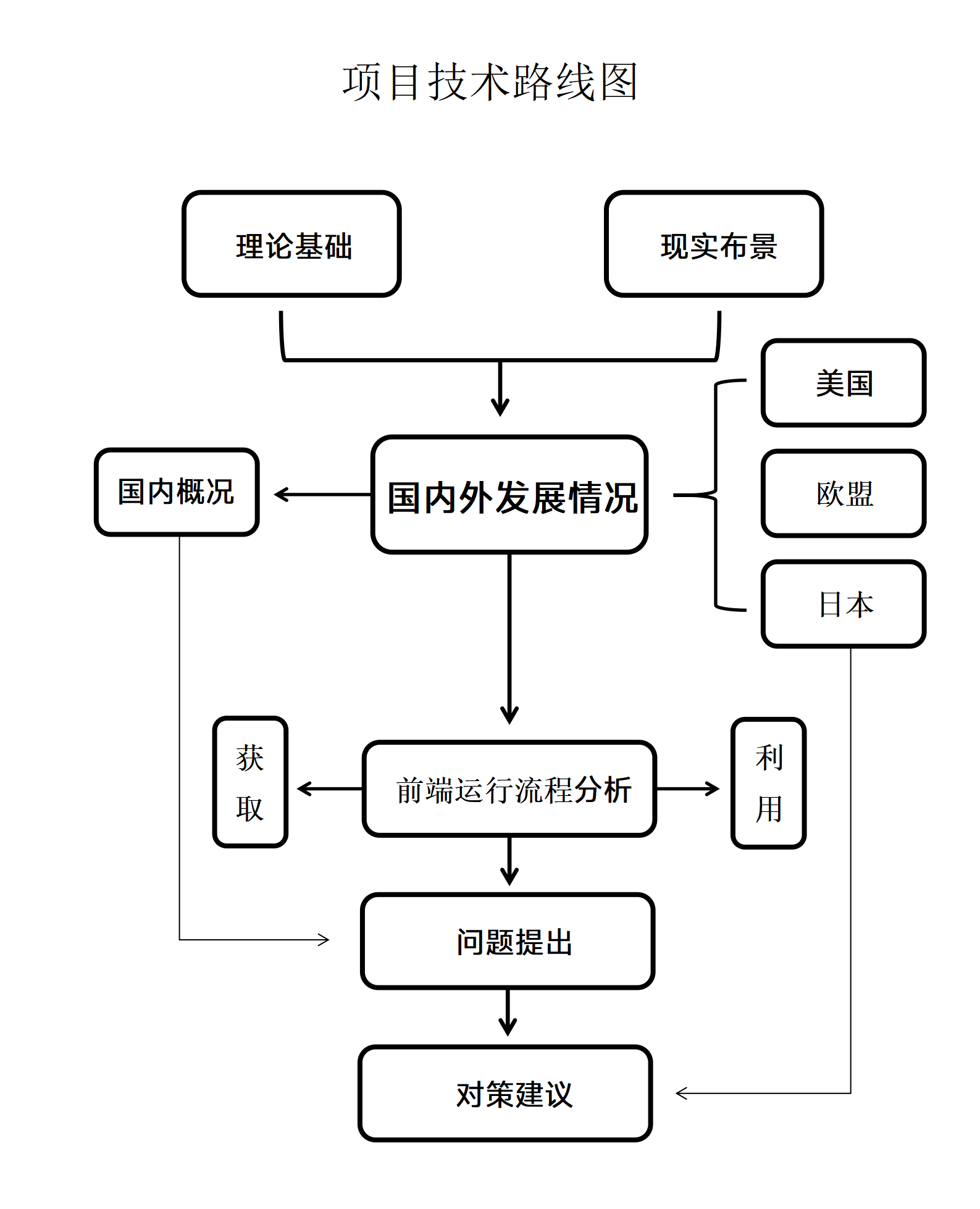
(一) 国内研究现状
关于人工智能数据获取与利用的著作权侵权问题,国内相关研究主要涉及以下方面:
1. 人工智能数据获取与利用之侵权风险
对于人工智能“数据获取与利用”行为是否构成侵权以及侵犯何种权利,国内学者有不同的观点。
在人工智能数据获取阶段,刘霜教授提出,生成式人工智能数据获取的手段可以分为自行采集数据、获取公共数据、购买第三方数据、爬取数据、数据创造,而生成式人工智能利用这些手段可以爬取拥有著作权的出版物内容,或通过其他网站获取侵犯他人知识产权的信息,会造成著作权侵权风险。购买第三方数据时,因为服务商本身并不对数据库或者其中的数据享有著作权或者不享有完整的著作权。
在生成式人工智能数据训练阶段,学者邓建鹏,朱怿成认为:由于生成式人工智能输出内容是基于前期投喂的数据库的自主学习训练过程,不受人工监督,获取的信息难以经过实质性筛选和过滤,数据在源头可能存在内容不合法不合规、内容虚假或完全错误的风险,致使人工智能生成物刚开始就带上了“原罪”的标签。
对于人工智能获取和利用数据时可能会侵害的权利类型,我国学界主要关注复制权和演绎权两个方面。焦和平教授认为在数据获取和利用环节可能会存在复制权的侵权风险。原因在于,人工智能进行深度自主学习之前,需要将作为创作素材的作品进行数字化处理并转换为适合“机器阅读”的标准数据格式。该过程是对已有作品在不改变内容情形下所进行的全文复制和原样再现,并且存储在机器中形成永久复制件,王迁教授认为,构成著作权法意义上的“复制行为”须满足两个条件,即应在有形物质载体上再现作品,而且作品应“固定”在有形载体上,因此该行为构成著作权法上的复制权侵权行为。若所生成式人工智能在前端采集的样本受著作权保护,马治国教授提出研究者或创作者利用扫描数字化等技术手段将样本复制在服务器的过程中,即使是多样性、间接性或短时性再现作品内容的样本采集行为,也存在侵犯作品复制权的风险。并且我国著作权法还规定了保护著作权的技术措施,在数据的获取阶段,可能会侵犯“控制接触型”技术措施和“控制利用型”技术措施,“控制利用型”技术措施是为了防止他人未经许可下载、传播作品,规避“控制利用型”技术措施可能造成对著作权人复制权的侵权。如果人工智能在数据分析阶段,没有直接使用原作品进行训练,则不侵犯原作品的演绎权;若是在原作品的基础上,进行一定形式的改编或者汇编,在未经许可的前提下,则可能侵犯著作权人的演绎权。同时,许可教授提出在生成式人工智能在通过网页爬取数据时,数据经过集合和汇总,可能成为编辑物、汇编物、集合作品或合成作品,受到著作权保护,可能会导致演绎权侵权风险。
2. 学界对于豁免其侵权风险的解答
学界对人工智能在数据获取和利用阶段复制权和演绎权的侵权问题现存在几种抗辩方法:合理使用一般情形,法定许可,及《著作权法》新增的“其他情形”。
首先,对于传统著作权的先授权后使用方法,彭飞荣教授认为生成式人工智能颠覆了传统的模式,“授权许可”难以实行。传统著作权法的规定并不能机械或简单的套用于算法创作的侵权处理中:一方面,算法的“学习”方式有别于人类的学习,无法机械适用传统规定;另一方面从经济成本角度考虑,机械适用会使得人工智能公司承担海量的著作权许可及相应的巨额费用,这不利于科学技术的总体进步与社会福祉的整体增加,甚至公司完全可能为了获取训练数据而转向“隐性侵害”,利用其他技术手段攫取他人作品数据这与著作权法规定的初衷相违背,无法有效保护著作权人的利益。其次对于合理使用,目前学界认为对于合理使用的几种情形均不适用于生成式人工智能,并且合理使用的司法解释仍须遵循“三步检验法”之限制。从法律适用角度来看,“三步检验法”首先要求其适用于“特定且特殊情形”,其次应符合“正常使用”,最后“应不得不合理损害著作权人合法利益”。但是从立法目的来说,“三步检验法”作为《伯尔尼公约》的宣示条款,旨在为各国立法做出原则化指示,而无统一明确法律内涵之目的。因此,“三步检验法”的三要件缺乏明确可直接适用的法定内核。学者张陈果认为要达成对著作权边界上各方利益公允、精准的平衡,就必须明确著作权限制与例外的一般条款-“三步检验法”的具体内涵,尤其第二步(“是否与作品的正常使用相冲突”)和第三步(“是否不合理的损害作者的合法权益”,其制度内涵和利益平准则,更是有待明确。目前,国内学者多认为“特定”“特殊”的指代情形以《著作权法》第二十四条所列举的情形作为特定法源。对于“特定”“特殊”的理解适用,司法者只能“找法”不能“造法”。同时,彭飞荣教授通过深入探究发现,在“思想表达二分法”规则之下,生成式人工智能模型对于他人作品思想、风格层面的“学习训练行为”实际难以落入既有著作权法专有权利的规制范畴,既然目前上述作品利用行为本身不受著作权法规制、不构成著作权侵权,合理使用的责任豁免便无从谈起。
再次,《著作权法》规定了四种法定许可制度,分别为第25 条第1款“编写教科书法定许可”、第35 条第2款“报刊转载法定许可”、第42 条第 2款“制作录音制品法定许可”以及第46 条第2款“播放作品法定许可”,除此之外在《信息网络传播权保护条例》中,规定了“制作和提供课件的法定许可” 以及第9条“向农村提供特定作品”这一准法定许可制度。法定许可制度与合理使用一样,均是法律对于著作权的限制性规定,因此均设置了严格的适用要件,并且法定许可制度仍需要向著作权人支付报酬。熊琦教授认为目前我国法定许可、强制许可付费的方式被批评为过于繁琐且对技术和市场变化的反应不足。学者王楷文认为,合理使用仍是人工智能数据输入最理想的制度选择,将数据输入纳入合理使用、在合理使用条款下仓设单独的数据输入例外,不仅具备充分的可行性,也具备充分的正当性。相比之下,法定许可集体管理模式有些纸上谈兵的意味,并不具备可行性。
最后关于我国著作权法新增的“其他情形”。在著作权法修法过程中,理论界和司法界有李琛、冯镇波、李扬等众学者主张引入合理使用一般条款,实现开放式立法。在此思想影响下,我国《著作权法修订草案送审稿》第
43 条第1款增加了“(十三)其他情形”。基于此稿规定,学者詹启智认为该规定不符合国情等建议删除,学者孙山也认为兜底款项欠缺正当性,与法理、实践均不合,纯属多余。在我国《著作权法修正案(草案)》中,并未给“其他情形”留下空间。此阶段的修正案从形式上采纳了詹启智、孙山等封闭式立法建议,看似给司法者留下了空间,实际上却牢牢限制住了灵活适用的空间,原因在于权威释义指出只有法律、行政法规规定的其他情形,才能构成合理使用。
因此,将国内对于人工智能数据获取与利用的著作权侵权问题整合研究后可以看出,国内对于人工智能侵权数据获取与利用的著作权问题争议较大。并且国内对于在人工智能数据获取与利用阶段使用他人已有作品是否构成侵权,对于现有权利的侵犯是否仅包含在复制权的范围之内,是否会构成演绎权的侵犯,国内现有立法及研究及研究且并未作出明确的规定,因此,本项目将通过了解人工智能前端数据获取与利用的运行原理,旨在准确理解与把握人工智能在该阶段著作权侵权问题,在此基础上借鉴国际立法并结合中国实际,探求科学、合理的化解之道,从而提出创新性解决方案。
(二) 国外研究现状
在大数据时代,文本与数据挖掘(Text and Data Mining,TDM)这一创新技术采用文本分析的方法处理海量信息,是推动生成式人工智能发展的重要工具。在生成式人工智能前端数据的接触和采集阶段,也就是数据获取阶段发生的著作权侵权行为该如何规制,以及如何寻求创新发展与著作权保护的平衡点是一个亟待解决的课题。对此,我们以欧盟、美国、日本为例,探究国外立法现状。
1. 美国
美国没有从立法角度解决
TDM面临的著作权困境,而是在判例中通过概括性适用合理使用条款认可了TDM 的合法性。针对数据集合的技术措施,美国《数字千年版权法案》虽然规定未经授权严禁规避技术措施,但是在行政执法、图书馆保存等七种例外情形下排除适用。然而,TDM 既不属于现行美国《著作权法》明定的七种例外情况,也未落入美国国会图书馆颁布的第七次审查中,排除适用禁止规避条款例外情形的范畴,故只能依据“四要素分析法”判断 TDM 是否成立合理使用。
对于第一要素,美国法院主要考察作品利用行为的营利性和“转换性利用”。在
Authors Guild v.Google, Inc.案中,法院认为扫描大量图书以建立电子数据库的“谷歌数字图书计划”属于“转换性利用”的情形。可见大规模扫描图书全文建立电子图书数据库的复制行为成立合理使用,那么接近这类情形的 TDM 也较易成立合理使用。
针对第二要素,美国法院重点考察所利用作品是否具有著作权法意义上的原创性。在 Campbell案中,联邦最高法院认为作品的原创性越高越易获得保护,则利用原创性越高的作品越难以成立合理使用。在
TDM 样本中,可能存在原创性较低的作品而较易成立合理使用,但也可能存在原创性较高的作品而较难成立合理使用,故
TDM 在这一要素中是否成立合理使用存在不确定性。
第三要素可归纳为分析使用作品的“量”与“质”是否合理。在原作品被利用的“量”方面考察原作品被复制的范围是否超出利用目的所必要的范围。在原作品被利用的“质”方面,考察原作品被利用的程度以及用途,即考察利用内容对原作品整体的重要性。基于“全数据采样”的技术特性,TDM从“量”方面较难成立合理使用。但
TDM 的本质是分析数据而不是使用原作品的表达,因此
TDM 从“质”方面较易成立合理使用。综合“量”与“质”方面的影响,这一要素难谓全然有利或不利于
TDM成立合理使用。
对于第四要素,分析合理使用的关键是作品利用行为是否会减损原作品的市场价值或潜在价值。因此,在
Harper &.Row, Publishers, Inc.v.Nation Enterprises 案中,杂志社未经授权从即将出版的福特总统回忆录中摘录最具新闻价值的内容不仅会产生替代效应,而且已损害作者的发表权不能成立合理使用。由于 TDM 侧重于分析而非表达,原作品的市场需求不仅不会因为TDM而受损,反而可能因TDM而促进原作品的再次传播通常不会发生替代原作品市场价值或潜在价值的情形。此外,TDM 不是原作品的创作目的,故TDM 市场不属于原作品的潜在市场,这一要素有利于TDM成立合理使用。
综上,在文本与数据挖掘著作权例外方面,美国司法实践通过转换性使用这一著作权合理使用的情形,甚至将商业性文本与数据挖掘著作权例外纳入著作权合理使用范畴,可见美国司法实践对于文本与数据挖掘技术的发展,无疑具有深远意义。
2. 欧盟
在制定《数字化单一市场版权指令》之前,欧盟限制规避技术措施的规定主要是《欧盟信息社会版权指令》。该指令优先鼓励权利人自愿达成排除适用禁止规避技术措施条款的协议;在双方没有约定的情况下法律才介入要求各成员国采取适当措施确保使用人的规避行为享有指令第5条的例外规定,同时这些例外规定也是当事人自愿达成协议的最低标准。虽然
TDM可能因为符合科学研究或教学目的条款而不构成侵权,但是能否适用这些法律规定具有不确定性。为了解决 TDM
法律适用的不确定性,欧盟起草并颁行了《数字化单一市场版权指令》。
该指令允许有条件地执行TDM 行为,但前提条件均为利用人必须通过订阅数据库、签订使用协议或在线开放等方式合法获取作品,即若研究者或创作者合法获取了数据集合的作品内容,则阅读该作品内容的权利应包含TDM的权利。欧盟要求成员国立法允许研究机构和公共文化遗产机构以科学研究为目的对其合法获取的作品进行复制、提取等 TDM行为;制定一般性TDM
限制规定,允许以 TDM 为目的对合法获取的作品进行复制与提取的行为。此外,为了进行TDM而临时复制的数据可能需要留存一定期间,要求应将临时复制的作品内容储存在可靠第三方管理的安全环境中,并且规定成员国应鼓励权利人和研究机构、公共文化遗产机构达成实行上述储存管理和技术措施的通用做法。
综上,可以得知欧盟认为在特定情形下,文本与数据挖掘包含被著作权保护的行为,例如对于作品的复制,从数据库中提炼内容等。在没有文本与数据挖掘著作权例外的情形下,文本与数据挖掘行为需要获得权利人的授权。
3. 日本
日本《著作权法》对文本数据与挖掘,即TDM采取比较开放包容的态度,认为运用TDM的过程中对作品的使用属于“非表达使用”,即认为生成式人工智能通过TMD技术来生成作品是一种“辅助工具”,而不是一项“创意作品”。原因在于,日本认为在TDM处理过程中,计算机利用函数来解析数据集合内作品内容并生成分析结果,无法像人类阅读时那样欣赏作品内容,难以威胁到著作权人的权利。因此,日本一方面通过《著作权法》和《不正当竞争防止法》制度规范禁止规避技术措施的行为,另一方面通过修订多项著作权限制性规定以放宽TDM情形下的作品使用例外规定。
日本《著作权法》第
2 条第 20 项对技术措施做出严格定义,即技术措施是防止或限制侵害著作权的技术,仅处分针对“控制利用型”技术措施的规避或准备规避行为,而不涉及“控制接触型”技术措施。这种制度规范禁止规避技术措施的条款,减少了技术措施对社会公共利益的负面影响。可见,多数以TDM为目的而规避“控制接触型”技术措施的行为不受日本《著作权法》的限制。
2018 年日本修订《著作权法》,新法不仅新增了不以欣赏作品表达为目的的要件,而且在必要使用限度的应用情形中增加了信息解析情形,而信息解析正是 TDM的处理方式。并且规定服务提供商在利用计算机处理信息产生新信息并将其结果提供给受众的过程中,允许轻度利用他人作品。即,若利用部分占整个作品的比例较低,且对作品市场收益影响轻微,那么在符合初始行为目的的前提下,可以在利用计算机处理信息产出以及提供分析结果的 TDM过程中利用作品。
综上,日本对TDM采取比较开放包容的态度,设置了许多例外情形,对人工智能发展起到了极大地推动作用。
 大学生创新创业训练计划管理系统
大学生创新创业训练计划管理系统